これは 呉高専 Advent Calendar 2022 - Adventar の14日目の記事です。
大遅刻、大変失礼しました…
しっかり埋まっていてすごい。そしてアルゴリズムからハードウェアまで、カバー域広い… 改めて、アドベントカレンダーを通して知らない人とつながれるのでとてもいい文化だなと思ってます。
まえがき #
2022年の6月にオープンセミナー2022@広島に「データ分析基盤のはじめかた」というタイトルで登壇させていただきました。
データ分析基盤の構成要素など考え方を中心の内容で、最後にデモを行いました。
セミナーでは実装の詳細に触れることができなかったので、この記事では connpass API をデータソースとしてデータ分析基盤を作って動かす方法を紹介したいと思います。1
この記事を通して、データ分析基盤をもっと身近に感じてもらえると願ったり叶ったりです。
対象読者 #
- データ分析基盤構築の一連の流れが知りたい方
- 普段は構築済みのデータ分析基盤を使っていて、その実装に興味のある方
デモ #
こちらにリポジトリを公開しています。

clone して docker-compose build && docker-compose up で動くはずです。気長に待ちながら続きを読んでもらえるとこの上ないです。
データ分析基盤の構成要素 #
実際に動かす前に、データ分析基盤の構成要素について触れておきます。
基本的な構成要素 #
データ分析基盤は、基本的には以下の要素で構成されます。
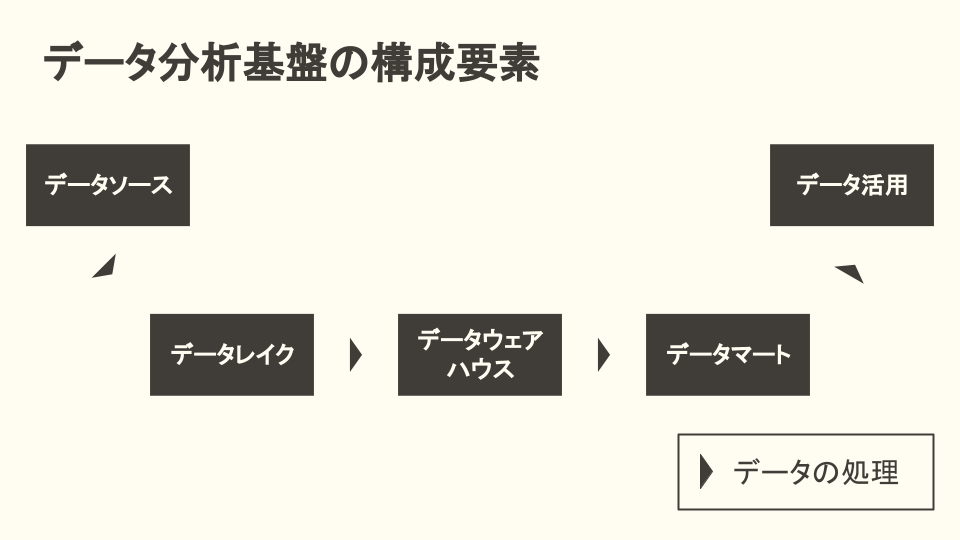
それぞれ、以下のような位置づけになります。
| 要素名 | 内容 | 具体例 |
|---|---|---|
| データソース | データの供給元 | Google Analytics の生データやセンサーデータなど |
| データレイク | データソースから受け取った生のデータを保存するストレージ | S3 や Cloud Storage などのオブジェクトストレージが選定されることが多いです |
| データウェアハウス | データレイクの生データを、分析が容易な構造化データとして保存するストレージ | BigQuery や Redshift、Snowflake などが選定されることが多いです |
| データマート | データを利用しやすいように、データウェアハウス内の構造化データをさらに加工したもの | 実体としては、ストレージは基本的にデータウェアハウスと同一になるはずで、データウェアハウス内の一部のビューやテーブルを指してデータマートと呼ぶようになります2 |
| データ活用 | データの活用先 | 機械学習モデルやその実装に利用する Jupyter Notebook、BI ツールなどがこれに当たります |
| データパイプライン | 上画像の矢印の部分。データ抽出や変換、ローディングなどを行う役割です | fluentd や Embulk、 Airbyte や dbt などの SaaS や OSS がよく挙げられますが、FaaS ベースの独自のスクリプトもデータパイプラインと言えます |
具体例としてオブジェクトストレージや列指向データベースなどを挙げていますが、あくまで選定される場合が多いものであって、例えば データレイクにはオブジェクトストレージしか採用してはいけない といったことは全くないです。
例を挙げると、 Google Analytics 4 (GA4) は BigQuery へのエクスポートが可能ですが、それを読み込んでデータ分析に活用するのであれば、 データソースは GA4 で、データレイクは BigQuery のテーブルという整理になります。
一方で、刻一刻と書き込まれる nginx のログは当然テキストファイルなので、それらを Cloud Storage にアップロードするのであれば、データソースは nginx で、データレイクは Cloud Storage という整理になります。
!!! note “曖昧になるデータレイクとデータウェアハウスの境界” ちなみに、近年ではこれらの構成要素がさらに洗練されてきています。
例えば、データレイクハウスと呼ばれる考え方で、オブジェクトストレージに ACID トランザクションに対応したファイルフォーマットで構造化データを保存して、非構造化データから構造化データまで一気通貫で管理する方法が取られることがあります。
一方で Google Cloud Next '22 では BigQuery の非構造化データへの対応が発表されており、 Cloud Storage に保存されたオブジェクトを BigQuery のオブジェクトテーブルとして読み出せるようになるようです。
このように、データレイクとデータウェアハウスの境界が徐々に薄れつつある印象があります。
データ転送を支える技術 #
先の項目では、ストレージに寄った話が中心でしたが、当然ストレージにデータを加工するための仕組みづくりが必要となります。それがデータパイプラインです。
そのデータパイプラインが具体的に行う処理をさらに細分化すると、基本的には以下の3つの順序と内容に集約されます。
- データの抽出(Extract)
- データの変換(Transform)
- データの書込(Load)
Extract, Transform, Load の頭文字を取って ETL と呼ぶことが多いです。
データパイプラインというと「専用のフレームワーク導入しなきゃいけないんでしょ?」と思ってしまいがちですが、必ずしもそういうわけではないです。
やっていることは単純なので、問題を作ってみました。
学生の試験結果が記録された以下のテキストファイルから、教科ごとの平均点を算出して subject, average の2列のカラムで CSV ファイルに保存してください。というお題があったとします。
"馬場 晃", "数学", 70
"広瀬 優心", "数学", 90
"馬場 晃", "国語", 80
"広瀬 優心", "国語", 70
Python で csv モジュールを使わずに書くと以下のような感じでしょうか。
# データの抽出(Extract)
scores = {}
with open("results.txt") as f:
results = f.readlines()
for result in results:
name, subject, score = result.split(",")
score = int(score)
if subject not in scores:
scores[subject] = []
scores[subject].append(score)
# >>> scores
# {'数学': [70, 90], '国語': [80, 70]}
# データの変換(Transform)
average_scores = []
for subject, values in scores.items():
average = sum(values) / len(values)
average_score = {"subject": subject, "average": average}
average_scores.append(average_score)
# >>> average_scores
# [{'subject': '数学', 'average': 80.0}, {'subject': '国語', 'average': 75.0}]
# データの書込(Load)
with open("average_scores.csv", "w") as f:
f.write("subject, average\n")
for average_score in average_scores:
subject = average_score["subject"]
average = average_score["average"]
f.write(f"{subject}, {average}\n")
ちょっと大げさに分けてみましたというのもありますが、基本的に ETL の流れになるはずです。
上記のような数十行程度の Python スクリプト や、単にオブジェクトストレージから BigQuery にロードする gsutil cp コマンドも、言ってしまうと暗黙的に ETL 処理とを行っていると解釈できます。
ただ特に退屈でメンテナンスに苦労するのが Extract と Load すなわち読み書きの部分です。 上記の例だとベタに書いているのでコード量は少ないですが、別のファイル形式で出力したいとかなるとまるっと書き直しです。
それらを解決するための技術として、先の具体例で挙げたような Embulk や dbt といった OSS や SaaS が存在します。
多くの OSS は、読み書きに関してプラグインやコネクタと呼ばれる形で実装されており、依存するストレージやファイル形式にあわせてビルトインやサードパーティのプラグインを利用したり、自分でコネクタ部分を実装できるようになっています。
!!! note “ETL 実装の省力化と、モダンデータスタック” 世の中には多種多様なデータソースやストレージサービスがありますが、新しいサービスに対応したり既存のサービスの仕様変更を追従し続けるのは困難を極めます。 E や L 以外にも、 T にあたる変換処理を実行するためのコンピューティングリソースの管理にも負荷がかかってきます。
それらの負担を軽減するために、 OSS や SaaS を組み合わせてデータ分析基盤を構築するアプローチがデータエンジニアリング界隈でトレンドになっていて、そういった構成を「モダンデータスタック」と呼ぶそうです。
どの仕事でも必要になる ETL の共通部分を OSS や SaaS にまかせて、自分にしかできない仕事に向き合える環境を作るという意味で、モダンデータスタックな構成はトレンドから当たり前のものになっていくものと考えられます。[^3]
ワークフローの管理 #
複数のデータパイプラインを用意して、それらに依存関係をもたせて順序立てて処理を行ったりしようとすると、スクリプトや CLI コマンドだけだと複雑になりすぎてしまいます。
そのような場合にはワークフロー管理ツールを導入することで、だいぶ楽をすることができます。 代表的な OSS として Digdag やApache Airflow や dbt などがありますが、身近なものだと GitHub Actions もその仲間と言えるでしょう。
データ分析基盤の構成要素のまとめ #
データ分析基盤の基本的な説明は以上です。細かいことはともかく、早く動かしてみましょう!!
!!! info “データ分析基盤についてもう少し詳しく知りたい方へ” もう少し詳しく知りたい方はセミナーの発表資料やアーカイブ動画があるので、よかったらご覧ください…
本格的に学ぶ際は、ぜひ[ビッグデータを支える技術 \[技術評論社\]](https://gihyo.jp/book/2021/978-4-297-11952-2)から読んでみてください!
データ分析基盤の仕様 #
方針 #
冒頭で言及したセミナー内のデモでは BigQuery を使い倒していましたが、できれば OSS をベースに誰でも気軽に試せるようにしたいです。
各要素を Docker コンテナで構築して、 docker-compose up でお試しできるようにしてみます。
仕様 #
- 10分毎に、指定したキーワードで connpass のイベントを検索してデータレイクに JSON 形式で保存する
- 1時間に1回、データレイクからデータウェアハウスにデータを転送する
- 1時間に1回、データウェアハウスのデータを加工してデータマートを作成・更新する
- BI ツールで connpass のイベントの参加者数の時系列推移を可視化する
!!! note “データ分析基盤におけるファイルフォーマット” connpass API のレスポンスの都合上、今回は JSON としてデータレイクに保存することにしましたが、一般的には JSON Lines 形式として1行1レコードに対応するように保存します。
JSON Lines 形式は、JSON で1ファイルごとに分けて保存する場合に比べて I/O のオーバーヘッドが小さくて済み、 CSV とは違ってヘッダー行がないので任意の行でファイル分割がしやすく、分散処理が行いやすいのが特徴です。
一方で圧縮効率やパフォーマンスの観点で、列指向フォーマットで保存しておく場合もあります。列指向ファイルフォーマットで代表的な形式として Parquet が挙げられます。
JSON Lines と比べてスキーマ情報を含められるなどの利点はありますが、人間からの可視性が低かったりデータ生成に一手間かかったりするので、データソースのフォーマットや保存方法にあわせて適切に選ぶ必要があります。
データ分析基盤のアーキテクチャ #
全体のアーキテクチャ #
ごちゃごちゃ手を動かした結果でもあるのですが、以下のようなアーキテクチャになりました。
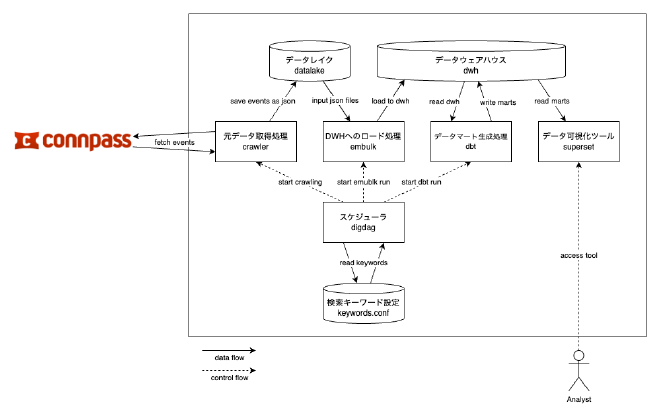
以下にデータ分析基盤の構成要素との対応表を示します。
| 要素名 | 採用技術 | コンテナ名 |
|---|---|---|
| データソース | connpass API | - |
| データソース -> データレイク | Python スクリプト | crawler |
| データレイク | Docker の Bind mounts 機能 | - |
| データレイク -> データウェアハウス | Embulk | embulk |
| データウェアハウス | PostgreSQL | dwh |
| データウェアハウス -> データマート | dbt | dbt |
| データマート | PostgreSQL | dwh |
| データ活用 | Apache Superset | superset |
| ワークフロー管理 | Digdag | digdag |
以降で、各要素について紹介します。
データソース -> データレイク #
connpass API #
データソースとして、言わずと知れた IT 関連のイベント主催・参加プラットフォーム「connpass」の API を利用します。
普段のイベントで connpass にお世話になっているのもありますが、認証が不要で API が利用できるので、ちょっとしたデモの実装や素振りに相性よく3、今回も connpass API を使います。
./datalake ディレクトリ
#
データレイクは Docker の Bind mounts 機能で、ホストの ./datalake ディレクトリにマウントしています。
crawler #
connpass API の結果を ./datalake に保存する処理は crawler コンテナが担っています。
中身は Python のスクリプトです。特に難しいことはしていません。
API からのレスポンスをそのままファイルとして保存しています。
crawler はデータ分析基盤というよりは元データの生成に近い役割なので、厳密にはデータパイプラインとも言い難いポジションだと思います。
データレイク -> データウェアハウス #
PostgreSQL #
データウェアハウスとして、身近な RDBMS である PostgreSQL を採用しました。
特に決め手となる選定理由はないですが、触ったことある人が多いと思われるのと、様々なデータエンジニアリング関連のソフトウェアにかなりの割合でコネクタとして対応している印象が強いので、そのまま気になるソフトウェアを試せるだろうという思いで選びました。
本当は DuckDB とか試してみたかったんですが、完全に時間切れ。
connpass.public.events というテーブル名で、1レコード1イベントとなるように格納されます。
Embulk #
データレイクからデータウェアハウスへの転送は Embulk でバルク転送することで行っています。実は今回のデモで初めて Embulk を使ってみました。
Embulk は設定ファイルに in, out を定義することで、どのようなデータをどのように出力するか読み取って、よしなに転送してくれます。
in と out の間に filter を定義することができて、今回は検索ワードそのものを keyword 列として追加するように指定しています。
データウェアハウス -> データマート #
データマート #
データマートの実体はデータウェアハウス、つまり PostgreSQL 内のテーブルもしくはビューとなります。
events テーブルから、用途に応じて柔軟にビューを切り出します。
キーワードごとに GROUP BY した結果をビューとして切り出したり、今回のデモでは用意していないですが他のデータソースを JOIN した結果をテーブルとして保持したりするのに用意します。
dbt #
データマートを生成するために dbt を利用 しています しようと思っています。
dbt は ETL 処理の T に特化したツールで、ソフトウェア開発のプラクティスをデータエンジニアリングに持ち込むことを宣言していて、私も仕事で使っていますが非常に開発体験が良いです。
Embulk とは違い、利用するデータウェアハウスの SQL 構文で、 SELECT や JOIN を使って取得したいデータや記述すると、そのクエリの結果がデータウェアハウスにテーブルやビューとして生成される仕組みとなっています。
SQL ファイルをモデルと呼びます。モデル内では Jinja Template が使えるので、dbt が用意した ref() マクロを使って、 SELECT * FROM ref('summary') のように他のモデルの結果を呼び出すことができます。これがものすごい体験がよいので、ぜひ使ってみてください。
ただ完全に時間切れで、今回は events をそのまま後述の Superset で可視化してみました。特に、2種類以上のデータソースを合わせ込む際に特に有用なので、ぜひ入門してみてください。
その他 #
Digdag #
crawler や Embulk や dbt は何らかのトリガーによって実行する必要があります。今回は実行トリガーを引く役割を Digdag に任せています。
Digdag はワークフロー管理ツールで、複雑なタスクの依存関係を定義していい感じに実行してくれるツールですが、今回は複雑な DAG は組んでおらず、高機能 crontab のように使っています。
今回は docker-compose 縛りだったので Digdag を使ってみていますが、 GCP であれば Cloud Scheduler と Cloud Pub/Sub を組み合わせて利用したり、 Kubernetes であれば CronJob ワークロードを利用したりするのが安定で手っ取り早いと思います。
データの処理を担う crawler, embulk, dbt には薄い Web API サーバーを起動しており、エンドポイントを叩くと run.sh を実行する作りとしています。ご想像の通り run.sh に Dockerfile でいう CMD 相当のコマンドを定義しておき、望む処理を実行できるようにしています。
Digdag では、指定したエンドポイントに http リクエストを送信する処理を定義できるので、各 API サーバーを一定間隔で叩くようにしています。
Superset #
BI ツールとして Apache Superset を採用しました。 単純に使ったことがあって慣れているので、 Superset を選定しました。
OSS にこだわらなければ、 Looker Studio (旧 Google データポータル)を使ってもよいと思います。
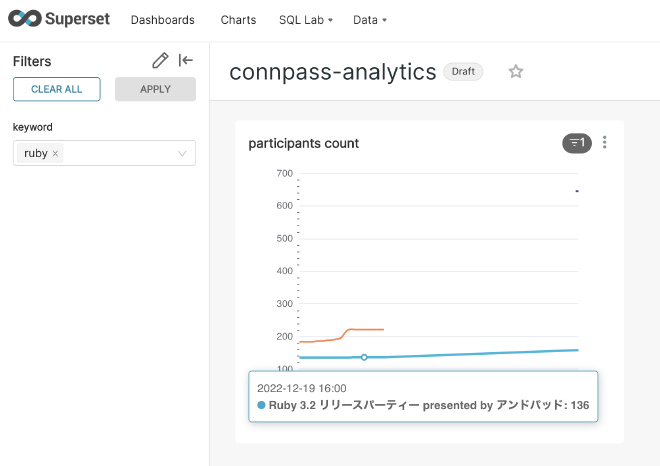
以下のように、任意のチャートを定義して、ダッシュボードで確認できます。(キーワード ruby で絞り込んで、イベントごとに参加者数の推移を表示しています)
まとめ #
以上で connpass のイベント情報を分析する、データ分析基盤のアーキテクチャとその実装の紹介を終わります。
具体的なツールの詳細までご紹介しきれませんでしたが、データ分析基盤が概念的にどういったもので、一例としてどういった実装になるのか、少しでもお伝えできれば幸いです。
やっていることは OSS の組み合わせで単純ではありますが、やっぱり様々なソフトウェアやサービスを味見しておいて、適切に選定できるように構えておきたいものです。(自戒の念を込めて…)
そして結局投稿日がクリスマスイブになってしまいました。明日はクリスマス当日、 @ihsot_6121 の記事の予定です。たのしみ!
!!! tip “今後の展望” ちょっと後半勢いに任せて書いてしまった感があるのと、 dbt の具体的な実装例が紹介しきれなかったので、また追ってコミットして、小出しに紹介できればと思っています。
それから、アクセス可能なデモとしては仕上がっていないので、少し UI 面を作り込んで用意したり、 Kubernetes でホスティングできるようにして、うちの宅鯖にデプロイしたいと考えています。